你好,我是 庄宏 — 慕尼黑工业大学(TUM)信息学硕士在读。我专注于大规模 多模态与强化学习模型 的训练、扩展与加速。
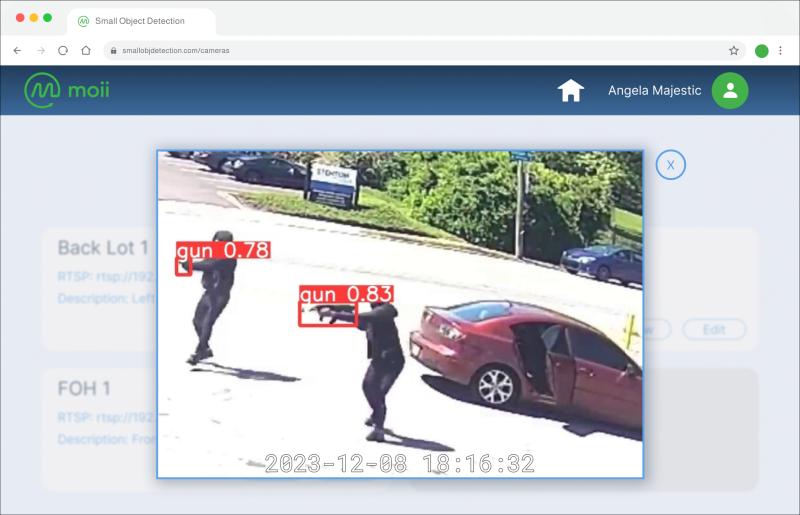
目前在 腾讯混元基础组(AI Infra) 做推理框架实习,负责跨芯片算子精度验证统一框架与 vLLM 推理加速。此前在 华为昇腾模型中台 主导了 Wan2.1 14B 文生视频模型的长序列并行优化(与京东联合创新)— GPU 用量降低 75%,显存下降 50%;更早在 Moii.AI 参与构建实时枪支检测系统,获得 Amazon Sigma Award。
兴趣方向:模型工程、算法落地、模型加速、推理框架。
Hi, I’m Hong Zhuang — an MSc Informatics student at the Technical University of Munich (TUM). I work on training, scaling, and accelerating large multimodal and reinforcement-learning models.
Currently interning on Tencent’s Hunyuan Foundation Group (AI Infra), building a cross-chip operator-precision verification framework and vLLM inference acceleration. Previously at Huawei’s Ascend Model Platform, I drove long-sequence parallel optimization for the Wan2.1 14B text-to-video model (a joint innovation with JD) — cutting GPU usage by 75% and memory by 50%; and earlier co-built a real-time firearm detection system at Moii.AI that won the Amazon Sigma Award.
Interests: model engineering, algorithm deployment, model acceleration, and inference frameworks.